27 Jun 2019 - OniroAI
The project repo: https://github.com/OniroAI/MonoDepth-PyTorch
Dense depth maps estimation is among crucial task for scene understanding, building perception system for mobile applications (e.q., for visual SLAM) and many other uses. In general, it is impossible to produce a depth map by only one given frame. However, in real-world cases, humans can perceive depth with one eye by taking cues from relative objects sizes, perspective, and knowledge of the features of objects. That is why it worths a try to train a neural network to estimate a dense depth map by a monocular view.
Monodepth[1] is an artificial neural network for this task which trained in a semi-supervised manner. It tries to find a disparity map between left and right frames captured with a synchronized pair of cameras (a stereo camera). It needs only one view on inference to predict a disparity map, which can be used to produce another view of the binocular vision system. Given the disparity map, one can estimate real depth provided a proper calibration is presented.
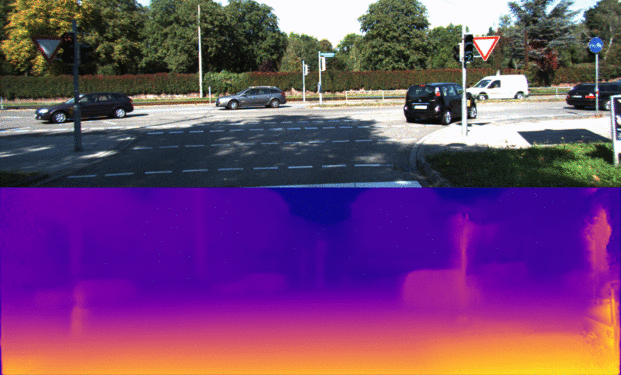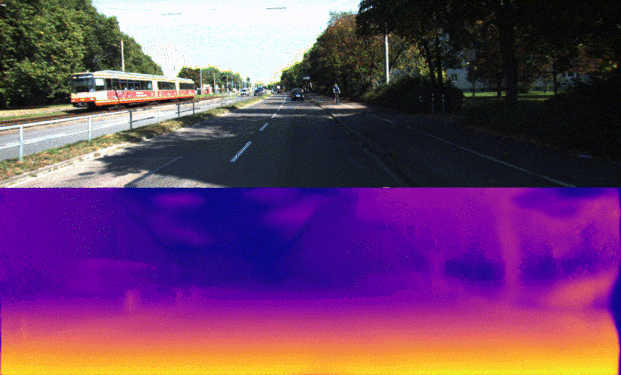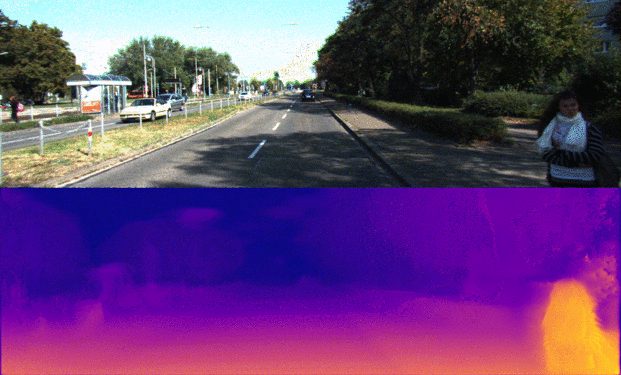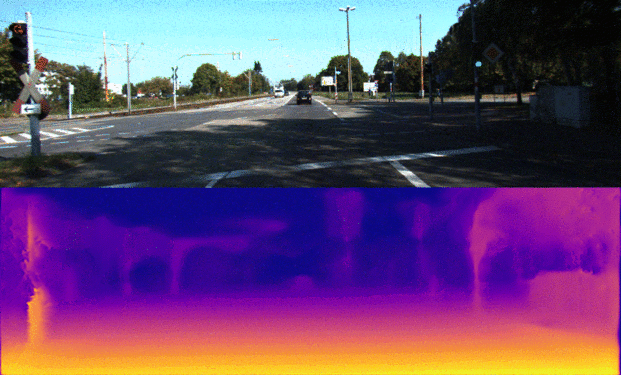
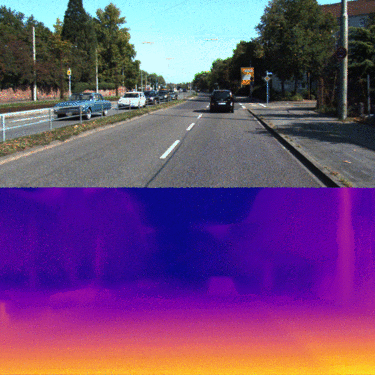
The overall goal of this project is the Monodepth reimplementation with PyTorch framework. The model architecture consists of a ResNet based encoder and a decoder with learnable upsampling. The main points of the current architecture are the utilization of skip connections from encoder by decoder and prediction of disparity maps at four different spatial resolutions. Using of skip connections allows enhancing precise object localization after upsampling with transpose convolutions while predicting disparity maps from feature maps at different scales is useful to combine rich semantic information and high resolution for small details of the image.
A pre-trained model with ResNet-18md encoder is available to download for experiments (see a link in the project repo. However, our implementation allows to choose an encoder from any ResNet architectures: 18, 34, 50 (as in the original paper), 101, and 152 as well. Moreover, ImageNet pretrained versions of all these encoders are available from torchvision and may be utilized by setting up one parameter during training.
Despite the fact that the model follows the original architecture, one should note a key difference of the presented implementation from the original TensorFlow code: batch normalization layers were added to improve training stability. Also it should be noted that Monodepth authors used one more lateral shrinkage than original ResNet network in the first ResNet block and it was reproduced in the ResNet-18md structure while all available models from torchvision follow the original ResNet architecture and lack this shrinkage.
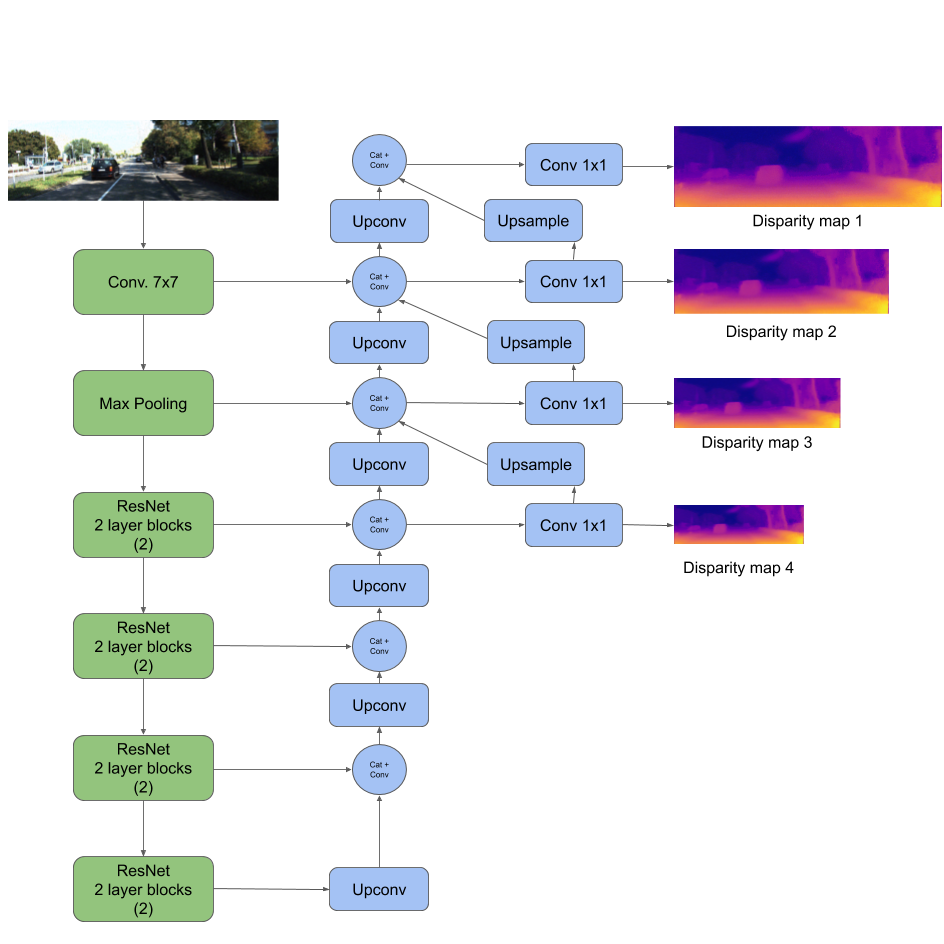
Monodepth model architecture with ResNet-18md encoder
Both left (l) and right (r) images are needed for every sample frame during the training stage. However, the right image is only needed to calculate loss because using only one left image model predicts l-r and r-l disparities and via bilinear sampler left image is generated from the right and the right image from the left thus enforcing mutual consistency and improving quality. This trick is the major contribution of the Monodepth authors. Enforcing consistency is possible through the use of a special loss function among three different components.
The first one is Appearance Matching Loss between sampled images via disparity maps and corresponding original images using SSIM as an image reconstruction cost (a simplified version with a 3x3 block filter instead of a Gaussian). The second one is Disparity Smoothness Loss which encourages disparities to be locally smooth with an L1 penalty on the disparity gradients. The third component is Left-Right Disparity Consistency Loss ensures coherence between disparities by making the left-view disparity map equal to the projected right-view disparity map as described above. The loss components are summed up with weights. The loss was calculated at each output scale which improves training speed and resulted quality.
The famous KITTI dataset was used during training as it is a common and versatile benchmark for algorithms of the kind and it provides all necessary data for training and assessment (binocular videos and ground truth lidar depth measurements).
The model was trained with Adam optimizer. Additionally, a step learning rate scheduler was applied (halving the original lr=1e-4 on every 10s epoch after the initial 30 epochs). Random gamma correction, color, and brightness shifts were used as augmentations as well as left-right image flips.
The original Monodepth paper was published quite a while ago, and some of its issues and limitations were addressed in succeeding studies.
One limitation of Authors of the original paper augmented their approach and SfMLearner [2] to utilize single-view monocular videos for camera pose and depth estimation tasks [3]. Moving objects make it difficult to predict a dense depth map with a sequence of video frames, captured with a moving camera. Partly, this constraint may be loosened by use of a dataset with stationary objects and camera pose estimation based on parallax cues from the static image areas [4].
Another limitation of the considered approach is the fact that it tends to “overfit” to a single camera setup (camera and lens), used for the training dataset collection and does not generalize to videos captured with different cameras. This limitation could be overcome with special convolutions CAM-Convs[5]. Basically, it is Coord-Convs with inherited information on the camera calibration, which could be added to the skip-connections of the U-Net style network.
It was also shown that such tasks could be treated with AutoML approaches, for example, DARTS could be applied for a neural network architecture search and BOHB - for hyperparameter tuning of the selected architecture [6]. As encoder-decoder neural nets are quite computational costly, it is important to find a way to optimize it for real-time inference while keeping the required accuracy level. It could be addressed with end-to-end joint pruning method [7] which learn a binary mask for each filter to decide whether to drop the filter or not along with the main depth estimation model.
References list: